When a Bloom filter really blooms....
Definition
Simply put, a Bloom filter is a space-efficient probabilistic data structure with which we can determine the probable existence of a certain thing in a certain data set, and we can determine the non-existence of a certain thing in a certain data set with utmost accuracy. Doing all this in a memory space efficient manner.
In a gist, Bloom filters are about determining if an element may be in a set or is definitely not in a set
Allowed Operations
You can only do one of the two operations on a given Bloom filter. You could still extend the Bloom filter to remove elements, but we stick to these two operations for discussion’s sake:
Insert a new element - add
Check for an element - verify
Mechanics
The Bloom filter works by populating a bit Vector of a specific length. To understand Bloom filter, we need to understand Hashing. You might have used Hashing in a cryptographic context where you take a data of arbitrary size, run it through some algorithm, and you get back a value that is of a fixed size or often times called the hash value. Most of the time such hash functions are one way operations. Why do we care about Hashing by the way for discussing Bloom filters? Using a simple non-cryptographic hash such as the murmur3 (multiply, rotate, multiply, rotate) is a good choice for doing lookup tasks based on hashes. It is a simple and a fast algorithm and finds its usage in common scenarios like checksum, id generators. So this becomes a natural choice for using with Bloom filters.
It is all about doing some math with the following four variables:
n: Represents the number of input elements
m: Represents the memory used by the bit-array or in other words, the size of the array
k: The total number of hash functions to be used
p: The probability of a false positive
The image below shows an empty Bloom filter with a bit array of size m (here 10 elements), initialized to 0 for all the elements.

Let us assume that for simplicity we just have k (the number of hash functions) set to 2, and our hash functions looks like this:
Hash Function 1 (H1) = input mod 2 => H1(“foo”) % 2 = 2
Hash Function 2 (H2) = input mod 6 => H2(“foo”) % 6 = 6
The result of the hash functions mean that we will set the corresponding bits in the Bloom filter array to 1. For example., at the bit positions 2 and 6, we will flip the values to 1 as seen in the image below:
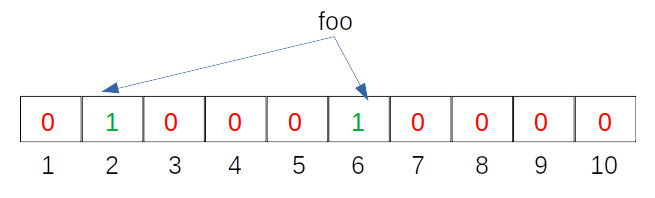
Let us now do the same for another entry:
Hash Function 1 (H1) = input mod 2 => H1(“bar”) % 2 = 4
Hash Function 2 (H2) = input mod 6 => H2(“bar”) % 6 = 8
We then set our Bloom filter indices accordingly, which is shown in the image below:
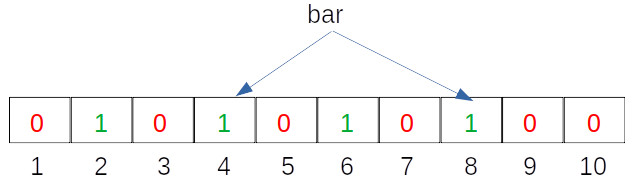
That's it, for our example's sake, we are done with insertion. Let us now check for the existence of a certain element in the Bloom filter! The lookup works more or less the same way as an insert where we run the text to be looked up through the hash functions, check if the indices are set to 1. If all the indices are set to 1, then we can say that particular text is probably present. If in case any one of the indices is not set to 1, then we can for sure say that the text is not present.
Let's test it for the text foo:
Hash Function 1 (H1) = input mod 2 => H1(“foo”) % 2 = 2
Hash Function 2 (H2) = input mod 6 => H2(“foo”) % 6 = 6
We can see from the populated Bloom filter that the indices at positions 2 and 6 are set to 1, so we have a potential false positive or a true positive or in other words we can probably say that the text might be present.
Let's test if for the text nope:
Hash Function 1 (H1) = input mod 2 => H1(“nope”) % 2 = 2
Hash Function 2 (H2) = input mod 6 => H2(“nope”) % 6 = 5
There we have a 0 at index 5, so we have a potential true negative or in other words we can for sure say that this text is not present. Yes, it is that simple!
We can indeed tweak the output of the Bloom filter by adjusting the size of the bit set. By adding more elements to the bit set, or the number of indices, we reduce the eventual probability of getting false positives. Probability of getting a false positive also decreases by increasing the number of hash functions.
The probability that a hash function sets an index to 1 in a set of m elements is given by:
$ P(1) = \frac{1}{m} -----> eq (1)
The probability that a given hash function fails to set an index to 1 in a set of m elements is given by:
$ P(0) = 1 - P(1) $ -----> eq (2)
From the laws of Probabilities, the sum of probabilities add up to 1, hence:
$ P(0) + P(1) = 1 $ rearranging, we get $ P(0) = 1 - P(1) $ -----> eq (3)
So we end up with the following probability for one hash function failing to set a given index or bit to 1:
$ P(0) = 1 - \frac{1}{m} $ -----> eq (4)
Hence, after we have inserted all the elements (say n) in the Bloom filter, by running through k number of hash functions, the probability that a particular index is still 0 is given by the following equation:
$ P(0) = (1 - \frac{1}{m})^{kn} $ -----> eq (5)
The above equation is based on the assumption that the hash functions are independent of each other. Now by substituting this value for P(0) in {{ textcolor(color="red" text="eq (2)") }} and doing a bit of re-arranging, we get the probability of a false positive:
$ P(1) = (1- [1 - \frac{1}{m}]^{kn})^{k} $ -----> eq (6)
With that being said, how do we choose the number of hash functions and the size of the bit array for the Bloom filter. It turns out that there are some formulas that hold good to determine them:
$ m = -\frac{n*lnP}{(ln2)^{2}} $ -----> eq (7)
$ k = \frac{m}{n}(ln2) $ -----> eq (8)
I'm trying to figure out how eq (7) and eq (8) works out, but for the sake of this article, we can use them to determine one value from the other.
Hash Functions
The choice of the hash functions that will be used should be independent of each other, i.,e the outcome of one of the hash function should not have any effect on the outcome of the other hash functions. The opted hash functions should be fast. It is recommended to use non-cryptographic hash functions like the murmur hash. Have a look here on why murmur3 should not be used in a security context.
The performance of the Bloom filter is directly proportional to the number of hash functions used, as there is a tendency for the Bloom filter to become slow when more hash functions are used.
I will probably revisit this content later on, but for now I'll wrap it up here!
Application & Usage
Where do we use Bloom filters - Everywhere where we want to do a look up and everywhere where the false positives can be tolerated!
Further Reading
A definitive article on Bloom filters could be found here
For an interactive show on how Bloom filters work, have a look here